
Web Scraping con Cheerio en VUE
En este post se va a tratar el Web Scraping. Esta técnica es utilizada para extraer información de páginas web. Es increíblemente útil cuando necesitamos recuperar grandes cantidades de información de diferentes páginas. Debido a que ahorra una gran cantidad de trabajo humano.
En esta ocasión utilizaremos esta técnica para recuperar los títulos de los posts publicados en la página principal de https://techriders.tajamar.es/
También recuperaremos las etiquetas de cada titulo y realizaremos un recuento para ver que temas son más abundantes.
Para realizar esta tarea utilizaremos la librería Cheerio. Una librería desarrollada para facilitar el scraping.
Creación del proyecto y dependencias
Lo primero que debemos hacer es crear un proyecto VUE:

Lo siguiente es movernos al directorio del nuevo proyecto e instalar las librerías que vamos a utilizar. En este caso son Cheerio y axios.



Ya hemos mencionado Cheerio anteriormente pero no axios. Para los que no conozcan esta librería, esta nos permite realizar peticiones http.
Lo que haremos será conseguir la estructura DOM de la página mediante una petición de axios y mediante Cheerio conseguiremos extraer los titulos y las etiquetas. Comencemos.
Petición HTTP mediante Axios
Lo primero que haremos será crear un nuevo componente donde trabajaremos, para ello haremos click derecho en la carpeta components y seleccionaremos New File. Elegimos el nombre que deseemos y le añadimos la extensión .vue
En este nuevo archivo abriremos una etiqueta template donde realizaremos el dibujo de la página y una etiqueta script donde diremos como se tiene que comportar la página.
Para evitar errores en la etiqueta template, nos exige tener algo que dibujar en todo momento. En mi caso he puesto una etiqueta h1.

En el script lo primero que haremos será indicarle la manera de exportar el archivo para que luego Vue sea capaz de funcionar correctamente por detrás, yo recomiendo ponerle el mismo nombre que el archivo.

Lo siguiente es indicarle a Vue que vamos a requerir axios y declarar las zonas donde vamos a trabajar en el script.


En siguiente lugar vamos a realizar una petición HTTP de toda la pagina de Tajmar y la vamos a visualizar por consola.
Primero creamos una variable con la ruta que vamos a utilizar

Creamos un método donde realizamos una petición get de axios hacia nuestra url. Posteriormente llamamos a este método dentro de mounted() para que cada vez que se monte la página se ejecute.

Antes de iniciar el proyecto, tenemos que indicarle a Vue que queremos que se nos muestre este componente. Para ello hay que modificar el archivo app.vue de la siguiente manera:

Ahora sí, iniciamos el proyecto para visualizar la estructura de la web de Tajamar.

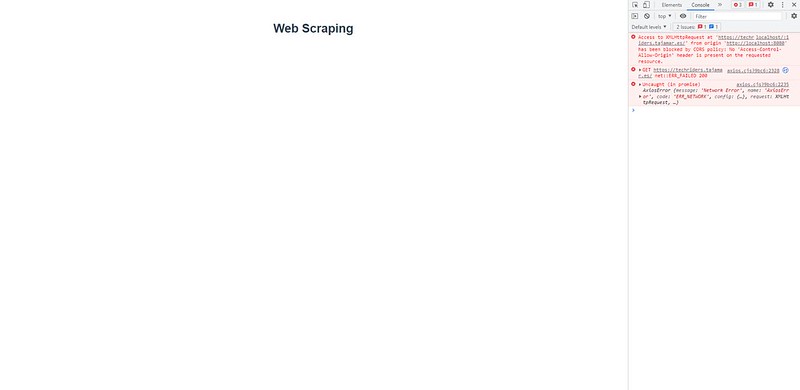

Como podemos comprobar, nos aparece un error en pantalla que a la vista parece bastante importante y complejo. Bien, ¿qué está ocurriendo y por qué no nos deja hacer la petición?
Muy sencillo, el CORS o Intercambio de Recursos de Origen Cruzado, es lo que está bloqueando nuestra petición. El CORS es una medida de seguridad que bloquea las peticiones HTTP desde un navegador hacia un servidor, justo lo que estamos buscando hacer nosotros. Pero, ¿significa esto que lo que intentamos hacer no es posible? No del todo, hay varias soluciones que podemos llevar a cabo. La primera sería crear nuestro propio servidor para lanzar desde ahí la petición, pero eso es tema para otro post, lo que haremos será utilizar otro servidor para realizar nuestra consulta.
Utilizaremos cors-anywhere.herokuapp.com. Para evitar que se use de manera indefinida el servidor, necesitamos pulsar el botón que aparece en su web. Además está limitado a 50 peticiones por hora. Con esto evitan que se sobreexplote su servidor.

Para indicar en el código que utilizaremos su servidor, cambiaremos la ruta de la petición axios.

Si volvemos a la página podremos ver que ya nos muestra por consola lo que buscábamos

Recuperar información mediante Cheerio
Bien, ya hemos recuperado al estructura de la página, ahora ¿cómo recuperamos los títulos y las etiquetas? Primero tenemos que hacer un trabajo de investigación sobre como está estructurada la web de Tajamar. Pulsamos F12 y buscamos donde están los artículos. Os invito a que lo hagáis vosotros mismos.
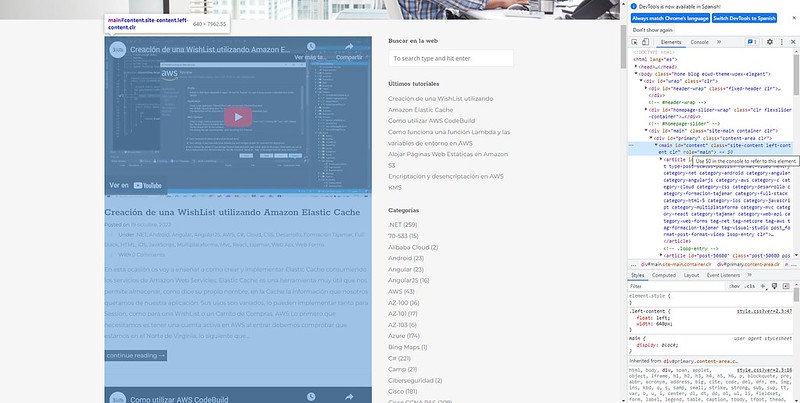
Tras rebuscar entre la estructura podemos ver que cada artículo es una etiqueta <article> y todas estas están dentro de una etiqueta <main>. Además, dentro de este <article> encontramos una etiqueta <header> que contiene todo lo que buscamos:

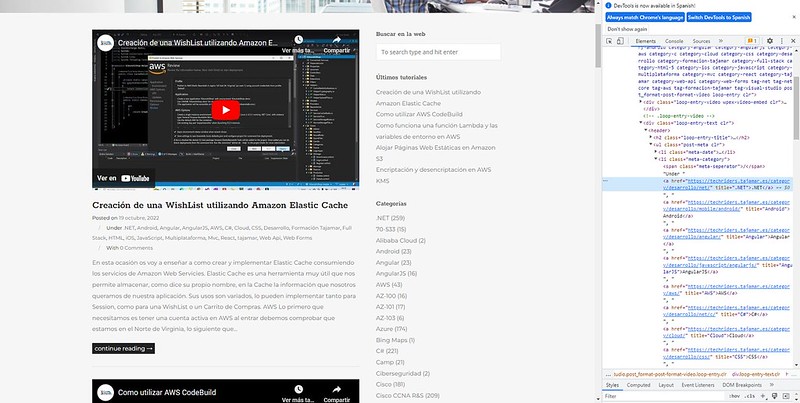
Es importante saber qué estamos buscando y dónde está ubicado para luego poder buscar entre el DOM de manera sencilla.
Volvamos al código. Indicamos que vamos a usar Cheerio del mismo modo que hemos hecho Axios antes.

Guardamos todo el html en una variable.
Guardamos toda la respuesta de la petición en una variable y creamos otra variable $ donde cargaremos el html mediante Cheerio.

A partir de aquí es dónde Cheerio entra en acción y saca a relucir todo su potencial. Lo que necesitamos en este momento es recuperar todos los artículos. Bien, lo haremos de la siguiente manera.

Lo que estamos haciendo es que recupere todas las etiquetas <main> del documento que a su vez contengan una etiqueta <article>.
Pero … ¿por qué no buscar simplemente todos los <article>? Bien, esto es un razonamiento lógico, pero hay que tener en cuenta de que puede haber una etiqueta <article> dentro de la página que no corresponda a ningún post. Por eso es importante concretar lo máximo posible en las búsquedas.
Una vez recuperado el artículo necesitamos que recupere su titulo y sus etiquetas.
Crearemos un array donde iremos guardando los títulos y las etiquetas que vayamos recuperando.

Antes de buscar el título repasemos donde está

El titulo está en una etiqueta <a> dentro de un <h2> que a su vez está dentro de un <header> y un <div> que está dentro del header. Una vez localizado lo buscamos en el código y lo guardamos:

Para repasar lo que estamos haciendo, cada <article> que esté dentro de un <main> lo recuperamos como “articulo” y le pedimos que dentro de este artículo busque la siguiente expresión:

El método text() indica que queremos recuperar solamente el texto. Si no llamásemos a este método recuperaríamos más cosas de las que necesitamos.
Hacemos lo mismo para las etiquetas, pero está vez habrá una diferencia. Si nos fijamos en la estructura de la página veremos que en un momento hay 3 etiquetas <li> y nosotros tenemos que acceder a una en específico.
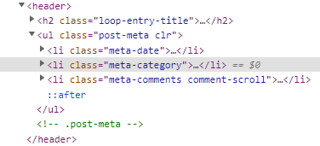
¿Cómo diferenciamos las etiquetas entre sí? Mediante sus clases.

Nótese que para diferenciar entre las etiquetas <li> indicamos la clase con un punto.
Como cada artículo puede tener varias etiquetas hacemos un bucle each de nuevo y recuperamos cada etiqueta y la guardamos en un array al igual que hemos hecho con los títulos.
Visualización de los resultados
Ahora que ya hemos recuperado toda la información que queríamos vamos a mostrarla en la página. Para añadir estilos usaremos la librería Bootstrap , en el archivo index.html añadimos las siguientes líneas .
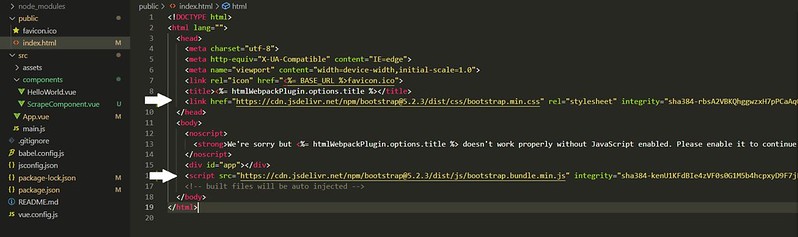
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.2.3/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-rbsA2VBKQhggwzxH7pPCaAqO46MgnOM80zW1RWuH61DGLwZJEdK2Kadq2F9CUG65" crossorigin="anonymous"> <script src="https://cdn.jsdelivr.net/npm/bootstrap@5.2.3/dist/js/bootstrap.bundle.min.js" integrity="sha384-kenU1KFdBIe4zVF0s0G1M5b4hcpxyD9F7jL+jjXkk+Q2h455rYXK/7HAuoJl+0I4" crossorigin="anonymous"></script>
Las peticiones Http no son instantáneas, por lo que no se mostrarán de manera instantánea en la web. Debido a esto sería conveniente añadir algún tipo de señalización de que la página esta cargando. Para ello creamos una variable booleana que se llame statusTitulos y la inicializamos en falso.

Lo que buscamos es que cuando se dibuje cuando todos los títulos estén cargados, por eso al acabar la petición http cambiaremos esta variable a true.

Ahora sí, lo dibujamos de tal manera que mientras que no haya cargado nos aparezca un gif de cargando. Para ello descargamos el gif que más nos guste y lo guardamos en el proyecto. En mi caso he creado una carpeta de images dentro de la carptea de assets y he guardado ahí el gif.

¡Ya hemos dibujado los títulos de todos los posts!
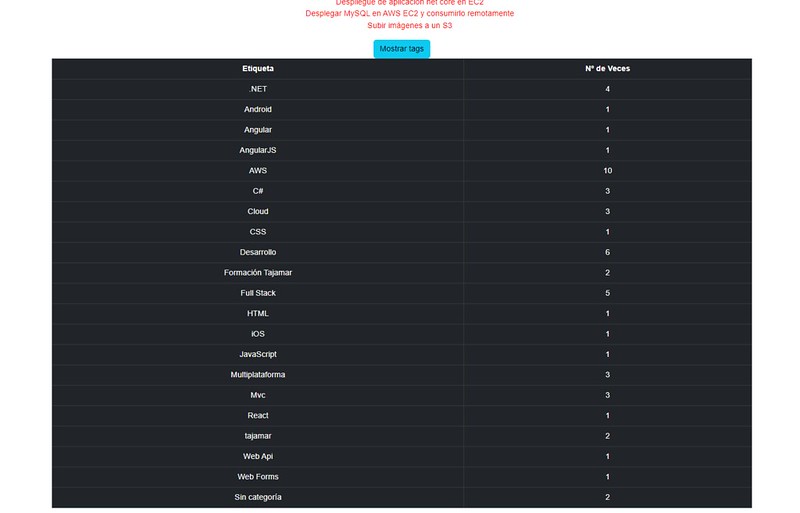
A continuación vamos a dibujar un botón que muestre un recuento de todas las etiquetas que incluyen estos posts y la cantidad de veces que han aparecido. Para ello crearemos un objeto vacío llamado contador y un booleano llamado statusTags:

Lo siguiente es crear un método que cuente todas las veces que aparece un item de un array y un método que cambie el estado del booleano para saber cuándo hay que dibujarlo:
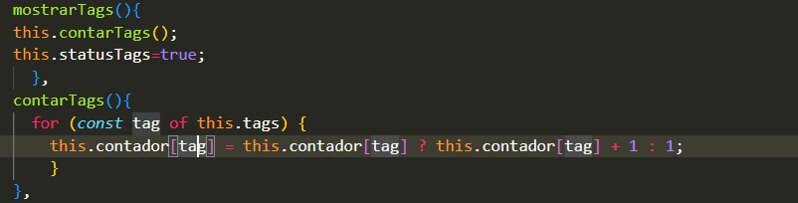
Ahora dibujamos el botón y lo enlazamos con el método mostrarTags() , que llamará a contarTags() y cambiara statusTags a true para avisar al dibujo de que muestre el recuento de etiquetas.
Vamos con el dibujo:
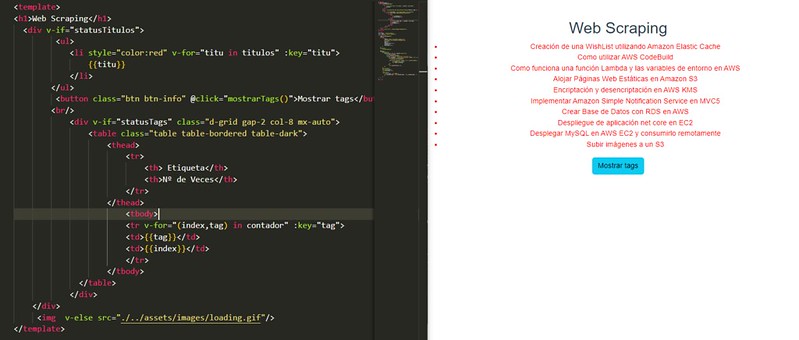
Pulsamos el botón y podemos ver la nueva funcionalidad
Hasta aquí el post. Espero que hayáis aprendido qué es el concepto de Web Scraping y que os haya picado la curiosidad con esta pequeña demostración.
Autor/a: Jorge Salinero Sánchez
Curso: Desarrollo Web Full Stack, Multicloud y Multiplataforma
Centro: Tajamar
Año académico: 2022-2023