
Post del Camp «OMS & Security Center: Juntos pero no revueltos»
Hoy nos acompaña Roberto Tejero, Solution Sales Specialist en Insight Technology Solutions, y podemos encontrarle en comunidades como ITPro, o su propio Blog personal
Se resume como consultor, ha trabajado en Bolsas y Mercados (BME), Ministerio de Defensa, Zerkana, Capgemini, y, felizmente en Insight … Especializado en Servicios de Infraestructura, Virtualización, Azure, Office 365, Power BI,y contenedores.

Hoy nos espera otra jornada llena de Azure, pero antes, Roberto nos cuenta qué es eso de OMS. (no es la Organización Mundial de la Salud) es el Operations Management Suite de Microsoft, anteriormente conocido como Logs Analytics.
En la consola de Azure, no se llama OMS sino Log Analytics. En el menú de Log Analytics, sale una “Blade” (esos cuadros adicionales de la consola de Azure, a medida vamos afinando el tiro cuando configuramos a través del portal de Azure) con el título “área de trabajo de OMS”. Es lo que tiene modernizar los nombres de los servicios. Lo que hoy se llama de un modo, mañana puede llamarse de otro.
A quien conozca alguna herramienta para análisis de reportes, seguramente le resultará familiar encontrarse una interfaz repleta de cuadros de seguimiento de uso de recursos, estadísticas de accesos, y dashboards modulares monitorizando distintos servicios.
Necesitaremos, de entrada, crear una instancia de Log Analytics dentro de nuestro portal de Azure (para lo cual hace falta una suscripción de Azure) para acceder a la interfaz del OMS y entrar en nuestro “portal de OMS” si queremos empezar a configurarlo.
Ahora, para que “enganche” con nuestros equipos y poder monitorizarlos, necesitamos el agente, que está disponible En la sección Settings, alcanzable pulsando la ruedecilla del margen superior derecho, tenemos unos enlaces para estos agentes tanto para arquitectura x86 como para x64, y conviene recordar que este agente es el mismo que engancha con SCOM (System Center Operations Manager). De hecho, en su instalación nos preguntará si vamos a conectarnos a OMS o a SCOM. Esto también puede ser desplegado de forma automática en las máquinas “autorizadas” por Azure, por si hay que monitorizar una infraestructura demasiado grande como para ir máquina por máquina instalando el agente.

¿Qué puede hacer OMS por nosotros?
OMS nos permite conectar con distintas máquinas, tanto Windows como Linux, o incluso nos permite crear herramientas de monitorización customizadas para analizar los logs de nuestra infraestructura, de cara sobre todo a labores de monitorización centralizada.
Tenemos, de entrada, algunos contadores de rendimiento para máquinas Windows y Linux. También IIS e incluso algo de Syslog, contadores que no solo apuntan a logs específicos de la máquina según su contador sino que también nos permite configurar algunos tiempos de consulta.
Tenemos también herramientas para importar objetos de grupos, WSUS, SCCM o nuestro ya conocido Active Directory, con lo que buscamos agrupar u organizar de algún modo las máquinas con las que vayamos a conectar a través del agente para extraer y analizar sus logs.
Todo eso es muy bonito pero ¿Cuál es el motivo que me lleva a extraer y analizar los logs de mi infraestructura?
Para todo aquel que haya monitorizado infraestructura alguna vez, esta pregunta tal vez no necesite respuesta. Para nosotros, la explicación es la siguiente: Las máquinas hablan en logs. Los logs lo son todo a la hora de preguntarle a un equipo “qué le pasa” o “cómo está”. Un inicio de sesión es un dato en un log, un encendido, un apagado, la ejecución de un servicio o tarea, también un error, un fallo, una advertencia, todo es un log. E incluso todo aquello que “todavía” no es un log, podemos hacer que sea un log. “Un log es lo que quieres que sea”
Los que se hayan atrevido con el Visor de Eventos de Windows habrán podido comprobar que el desafío con los logs no es simplemente “tenerlos”, sino pasar de esa tonelada y media de datos que figuran en el Visor, a información valiosa para el SysAdmin. No nos importa mucho saber si las máquinas ejecutan una tarea automática varias decenas de veces y esas tareas sale bien (tras comprobar doscientas entradas una detrás de otra), sino revisar, de forma rápida y fiable, si “todo está bien”.
Esto se ha venido logrando a través de estas herramientas llamada Log Analytics. Herramientas que convierten esa cuantiosa materia prima, que son los logs, en dashboards “legibles”, en cuadros de mando comprensibles en lenguaje humano (no siempre los logs hablan en humano… De hecho, rara vez lo hacen. Más bien casi nunca. Suelen devolver un valor numérico o un código de salida. Nuestro Visor de Eventos muchas veces traduce esos códigos por nosotros, aunque no reduzcan la cantidad de datos que vierte nuestra propia máquina). Si nuestra propia máquina es capaz de generar miles de entradas informando de su estado, de los servicios que se lanzan, se comprueban o se cierran cada hora, sólo hay que multiplicar esa cantidad por tantas máquinas como tengamos en nuestra infraestructura para darse cuenta de cuánto se necesita una herramienta de Log Analytics si queremos monitorizar por logs.
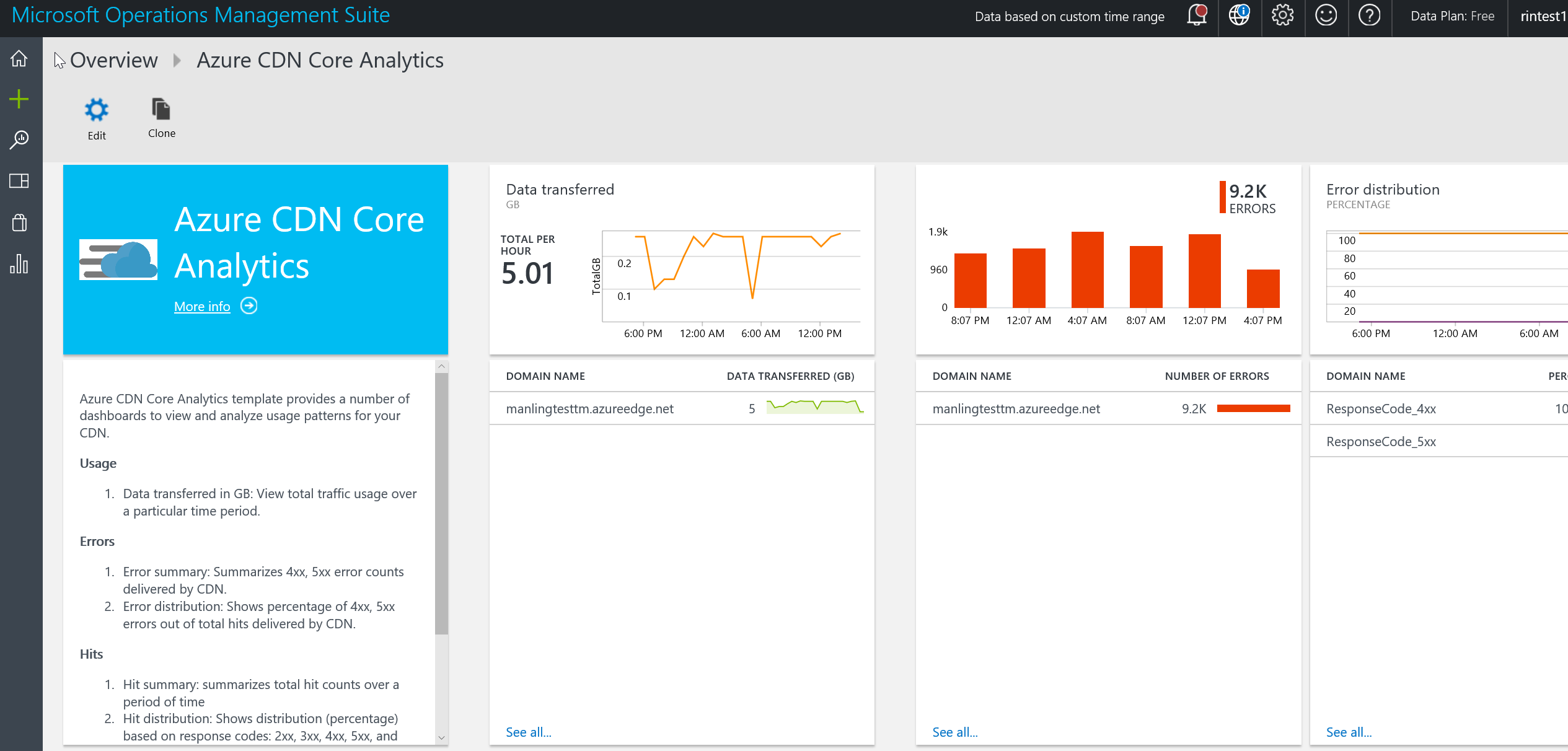
Volvamos a OMS. Sabemos ahora que OMS es el servicio en Cloud para recoger y analizar los logs de nuestra infraestructura, y ante este planteamiento, surge una duda razonable: Si la información la recoge un servicio en Cloud ¿Los equipos a monitorizar necesitan internet para tener enganche con el servicio? No necesariamente. Existen herramientas como OMS Gateway, para poder “cerrar” nuestra red, y mantener una mínima exposición, enviando los logs de nuestras máquinas al Gateway dejando a ese Gateway como único punto de enganche entre la Cloud y nuestra infraestructura.
En el ejemplo de hoy conectamos directamente con el servicio en Cloud, para lo cual necesitamos datos sobre la Workspace ID de nuestra instancia de OMS. Cuando conecte con nuestra OMS, nuestro equipo estará listo para enviarle la información de monitorización en función de la “solución” que se le aplique: el conjunto de logs que se consultarán en la máquina y enviarán hacia el OMS. Hay algunas soluciones que se instalan por defecto, como Seguridad y Auditoría o la Evaluación Antimalware.
Gracias al análisis de los logs de nuestra infraestructura, OMS puede detectar si algo falla, pero no se queda en la fase de “tienes un problema”, sino que además (al igual que SCOM), da indicaciones sobre cómo se pueden solventar los errores más comunes que aparecen.
Hay Soluciones para todos los gustos y colores en la Galería. Algunas son gratuitas, otras, más completas, complejas o “tailor-made”, que pueden ser de pago. Hay para monitorizar todo tipo de servicios que podamos tener en nuestra infraestructura: para bases de datos, para Office, para virtualización… Pero hay que tener la precaución de recordar que implantar muchas soluciones implican muchos datos subidos a la nube, que implica espacio disponible en la nube, que puede implicar coste adicional, por lo que la gratuidad de las soluciones no depende únicamente del coste de la adquisición de la solución, sino también del coste derivado de su implantación.
Nosotros implantaremos una solución que nos permitirá ver el mapa de servicios y el rendimiento de red. Esto implica dos fases, una en la que configuraremos esta solución en nuestro portal de OMS, y otra en la que configuraremos al agente para que envíe la información en función de la solución implantada.

El agente es bastante “bruto” en el sentido de que está programado para enviar prácticamente todo lo que encuentra, lo mete en un plaintext, lo cifra, lo comprime y lo envía al servicio en Cloud. El filtrado de todo lo recibido se realiza cuando el OMS recibe esos datos, y luego hay un segundo filtrado a la hora de establecer las “detecciones”: situaciones en las cuales los logs que recibe puedan indicar que “algo está pasando” (varios eventos de failed logon pueden indicar un posible acceso no autorizado). Esto es relevante no solo en el sentido de que el Cloud almacena sólo lo que consideramos “relevante”, sino que esto también puede implicar un tráfico de red entre la infraestructura y el OMS que debemos tener en cuenta. Esto se puede hacer de forma automática con las alertas ya configuradas, pero también podemos hacer nuestras propias queries para consultar a una máquina por logs específicos que nos permitan conocer su estado. Esas queries se mueven por un lenguaje propio, se parece a WQL pero no es exactamente WQL.
Vemos soluciones potentes (y muchas veces poco aprovechadas), soluciones de automatización a la hora de configurar los eventos que pueden constituir una situación “relevante” que requiera acción sobre nuestras máquinas, y soluciones para backups y para alta disponibilidad o redundancia de recursos.
Las queries son más una cuestión de ensayo y error más que de acertar a la primera. Pueden usar los elementos que vemos en un log: conocer nombres de variables implicadas como “type” “EventID” o “IPAddress” nos pueden venir bien a la hora de realizar un filtrado de logs que nos permitan identificar los logs de relevancia. Algunos caracteres como los asteriscos y el “piping” también se aceptan.
La última parte del Camp va sobre Security Center. De entrada, tenemos dos versiones, la Free y la Standard (Con las respectivas diferencias de capacidades entre la versión gratuita y la de pago). Lo que hemos visto, el camino desde nuestra máquina hacia nuestro tenant en Cloud tiene muchos pasos, muchos filtros de seguridad para evitar todo tipo de ataques. Azure Security Center permite controlar de forma unificada tanto las respuestas ante los posibles ataques detectados como la carga de trabajo, e incluso tiene recomendaciones incluidas para mejorar la seguridad de nuestra infraestructura.
Los códigos de evento de Seguridad de Windows son el estándar sobre el que se basa el Security Center para analizar eventos e informar al tenant en caso de que haya problemas. Cuanta más seguridad, más eventos suben al tenant. Más datos, más consumo… Más coste, tanto a nivel de ancho de banda como probablemente de almacenamiento (sin olvidar el licenciamiento, si queremos el Security Center de pago). Para filtrar los eventos de seguridad, funciona igual: va por queries. Otra dosis de ensayo/error hasta dar con los eventos que buscamos.
También comprobamos cómo la gente no pierde el tiempo. Nada más levantar máquinas virtuales en la nube, comienzan a saltar eventos de logons fallidos: intentan entrar en nuestras máquinas probando con los usuarios más comunes: administrator, admin, user… Las IPs desde donde nos dicen que intentan acceder son VPNs de países variopintos, desde Estados Unidos hasta Corea.

¿Y finalmente “qué quería decir con juntos pero no revueltos”?Las soluciones de OMS y Seguridad trabajan con la misma base: el análisis de logs, pero por lo que hemos visto, el Log Analytics no es exactamente seguridad, aunque sí podemos valernos del análisis de logs para garantizar la seguridad (sobre todo en el acceso) de nuestra infraestructura. Sería algo corto de miras limitar el uso del log analytics a la seguridad en exclusiva, cuando vemos que, si un log puede ser lo que queramos, el log analytics puede enfocarse un poco a lo que necesitemos monitorizar, si bien la seguridad es (o debiera ser) una de nuestras prioridades como administradores de sistemas.
Se va acabando este segundo Camp.
¿Qué sacamos en claro de hoy? Lo principal, es saber que, a la hora de monitorizar nuestra infraestructura, es buena idea contar con herramientas que permitan:
- Centralizar la gestión y la “visual” del estado de nuestra infraestructura
- Reducir la cantidad de datos mostrados a partir de los datos obtenidos, para dar únicamente la información relevante
- Integrar distintas tecnologías en una misma consola: distintos sistemas, hardware, servicios o programas
OMS cumple bastante bien con las tres cualidades, e incluso ofrece ventajas añadidas como:
- Dar opciones de ampliar las funciones de monitorización de forma centralizada (en la Galería de Soluciones), al poder agregar las Soluciones y hacer el “provisioning” de máquinas desde el propio portal.
- Incluye recomendaciones hechas en base a los resultados obtenidos de la monitorización de infraestructura
- Incluye soluciones que reducen los tiempos empleados en las tareas de configuración de alertas en base a los logs recibidos
Probablemente hubiéramos necesitado varios días para ver a fondo alguna solución más de las que se ofrecen en OMS, pero para un Camp de un solo día, creo que podemos concluir en que ha sido una jornada completa, exhaustiva, que no extenuante, para probar no solo una herramienta que puede venirnos a mano para monitorizar nuestra infraestructura y su seguridad en el acceso, tanto on-premise como de máquinas en la nube, sino también una herramienta extensible en sus funciones, en la medida en la que lo permiten sus Soluciones.
Terminamos la jornada con la foto de grupo, entre los asistentes y el ponente Roberto Tejero.
Muchas gracias a todos por haber estado esta jornada pasada por agua con nosotros y nos vemos en la próxima!

Documentación del Camp:
Autor: Gabriel Piuzzi Martínez y Victor Rodilla
Coordinadores Tech Club Tajamar
Alumno Máster Microsoft MCSA Windows Server 2016 + MCSE Cloud Platform & Infrastructure.
Año académico: 2017-2018